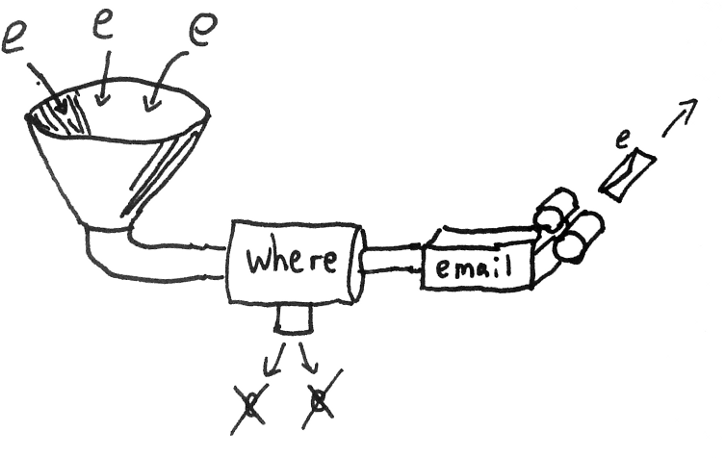
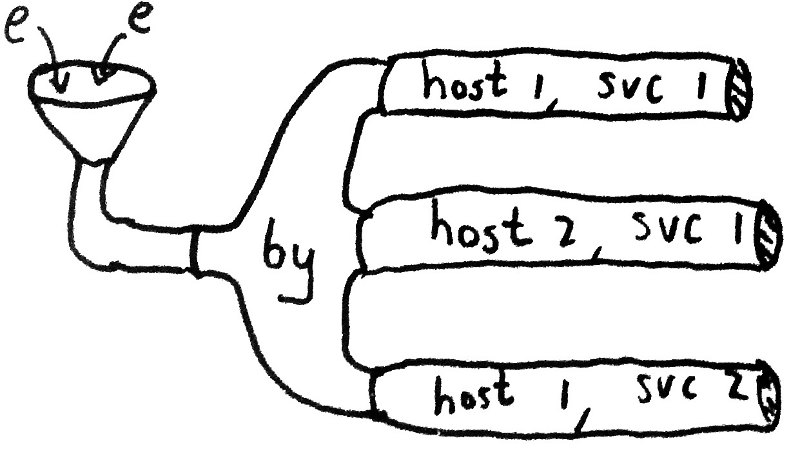
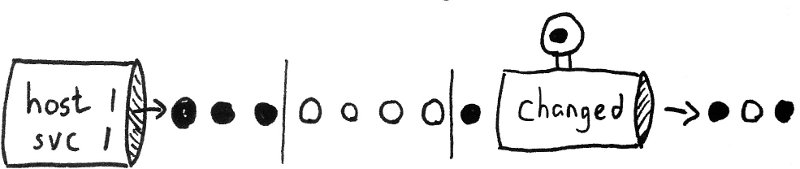
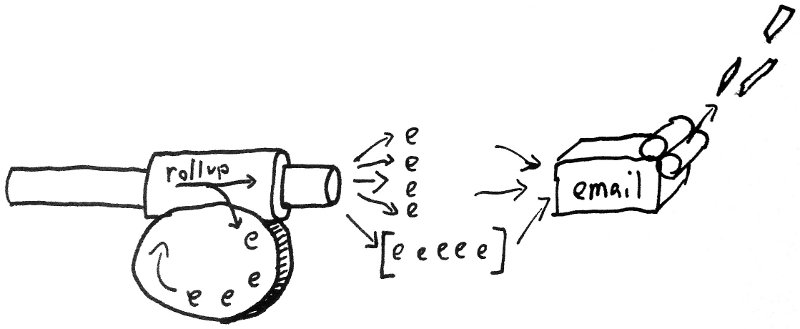
Riemann is an event stream processor.
Every time something important happens in your system, submit an event to Riemann. Just handled an HTTP request? Send an event with the time it took. Caught an exception? Send an event with the stacktrace. Small daemons can watch your servers and send events about disk capacity, CPU use, and memory consumption. Every second. It's like top for hundreds of machines at once.
Riemann filters, combines, and acts on flows of events to understand your systems.